
Hundreds of millions of events per month on the cheap
In this post, I'm going to go over the setup of infrastructure for creating an analytics platform capable of handling hundreds of millions of events per month. All without spinning up a single server.
I've recently had the opportunity to glimpse at how much some companies charge for this type of service, and it is shocking. For example, 150$ per 1 million data points. At 200 million events/month, that would be a 30,000$/month bill. Ouch!
Let's see if we can do better. Better-ish. I'm not going to tackle any sort of advanced reporting in this article. Arguably, that's the big value add that you get when you pay a SaaS provider for this kind of solution. Obivously you'll have to spend some time tinkering on building the reports you need. Even if you have to spin up a dev team to do so, at large scale it's probably cheaper than most SaaS offerings.
If you've already got a BI solution in your organization, this might be an easy win as integrating this into most BI suites shouldn't be too hard to do.
Dramatis personae
- Lambda: Serverless computing framework. This is where the code lives.
- API Gateway: The API interface that exposes the Lambda code to an HTTPS endpoint.
- Kinesis Firehose: Data ingestion pipeline. Buffers incoming data, and writes it out periodically to S3.
- S3: The file storage backend.
- Glue: The ETL processing framework.
- Athena: The data query layer
- Quicksight: The reporting layer.
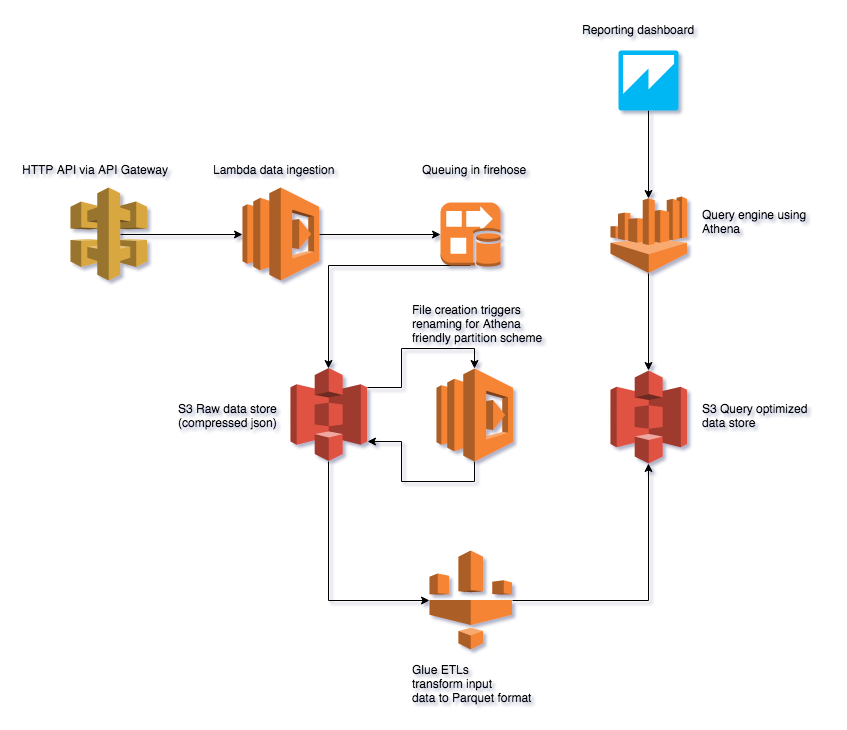
High level overview
Client code invokes the HTTP API endpoint that lives on API Gateway.
API Gateway, passes along the event to the Lambda function.
The Lambda function queues the data up in Kinesis firehose.
Kinesis firehose periodically dumps the data (in compressed form) to S3.
On file creation in S3, a Lambda function is invoked to rename the file (to follow Athena paritioning naming conventions).
On a regular schedule, a Glue ETL is kicked off to transform the JSON files in S3 into the Parquet format, which is better suited for querying it in Athena.
Finally, data can be queried via Athena, and dashboards can be built using QuickSight.
Along the way, we'll also setup some crawlers in Glue to map out the data schema.
Implementation - Data ingestion
Make a place to store the data.
From the AWS console, let's create an S3 bucket. Choose the region of your choice, and give your bucket a memorable name.
If you want to, setup some lifecycle hooks to periodically delete old data.
I'd recommend you don't set the bucket permissions to public, that's just a bad idea. Once you're setup, time to move on.
Create IAM role for event delivery
Create an IAM role called firehose_delivery_role, with the following permissions (replace YOUR_FIREHOSE_NAME, YOUR_BUCKET_NAME, YOUR_AWS_ACCOUNT_NUMBER_HERE):
|
|
Setup the firehose
Head on over to Kinesis firehose, and setup your firehose. Use the following settings (make sure you change the firehose name and the bucket name):
Stream name: YOUR_FIREHOSE_NAME_HERE
Source: Direct put
S3 bucket output: YOUR_BUCKET_NAME_HERE
S3 prefix: analytics_raw
IAM role: firehose_delivery_role
Data transform: disabled
Source record backup: disabled
S3 buffer size (MB): 128
S3 buffer interval: 900
S3 compression: GZIP
S3 encryption: No encryption
This instructs Kinesis do dump your data in 128MB chunks, or every 15 minutes whichever comes first.
HTTP API
For the HTTP API, we'll use API Gateway and Lambda. I'm going to use the serverless framework which will take care of things like orchestrating the deployment of the Lambda, associating events to API Gateway and S3.
To start, let's get the serverless framework installed:
|
|
Next, we'll create a file for package dependancies and the serverless framework config (make sure you change the firehose name and the bucket name):
|
|
Create the config file serverless.yml:
|
|
The package config file: package.json
|
|
Install the deps:
|
|
Code for file s3mover.js:
|
|
Code for track.js:
|
|
Deploy the code
|
|
Check your progress
If everything went well, you now have a data ingestion pipeline setup that can receive nearly limitless amounts of inbound data, efficiently pushing it to an S3 bucket.
Let's test it out. Here's a little script you can run to hit your API and push some random events in.
(replace the URL and API key as per the output of sls deploy)
|
|
Create a file datagenerator.pl:
|
|
And run it
|
|
If all went well, you should see some output being printed out to the screen. Wait about 15 minutes and go have a look at your S3 bucket, you should see some data files.
Implementation - Data/Schema discovery and optimization
Create Glue DB
Head over to the Glue console, and create a database. Just enter DB name that you'd like. (eg: YOUR_ANALYTICS_DB_NAME)
Create Glue crawlers for raw data
Head to crawlers, and create a new one. The parameters are:
Name: raw_discovery
db: YOUR_ANALYTICS_DB_NAME
table prefix:
ServiceRole: create one, needs to have AWSGlueServiceRole- as the name prefix
Selected classifiers:
Data store: S3
Include path: s3://YOUR_BUCKET_NAME_HERE/partitioned_analytics_raw
Save/Run it. Will create a table in your Glue DB
Create a trigger to schedule the crawler to run once an hour, this will keep the Athena meta-data up to date with the partition list.
Create ETL job to transform raw json files to parquet
Here's a python script that will transform your raw json files to Parquet. When creating the ETL, make sure you enable job bookmarks in the advanced settings. Make sure you change YOUR_BUCKET_NAME_HERE and YOUR_ANALYTICS_DB_NAME to match what your settings.
|
|
Run the job, you should now see a new path in your S3 bucket that contains partitioned Parquet files.
Probably a good time to create a trigger to have the job run every hour or day.
Create a crawler for the Parquet files
Head to crawlers, and create a new one. The parameters are:
Name: parquet_discovery
db: YOUR_ANALYTICS_DB_NAME
table prefix:
ServiceRole: create one, needs to have AWSGlueServiceRole- as the name prefix
Selected classifiers:
Data store: S3
Include path: s3://YOUR_BUCKET_NAME_HERE/analytics_data
Save/Run it. Will create a table in your Glue DB
Create a trigger to schedule the crawler to run once an hour, this will keep the Athena meta-data up to date with the partition list.
Review of what we have so far...
You're almost done. At this point you have a data pipeline that is ingesting data from an HTTP api, and pushing it into a query friendly format.
This pipeline should scale to just about any size, as all the pieces of the puzzle auto-scale based on throughput.
(assuming you've set the limits in your AWS account accordingly).
Querying the data
We can now query the data using AWS Athena. Head on over to the Athena console, and you'll find a database with two tables.
On table queries against the partitioned JSON files, and one queries against the Parquet format files.
To test things out, I've populated S3 with a year's worth of data similar to the data produced by my test script above.
The size of the data set is 20GB of compressed JSON files, partitioned over year/month/day. It represents the equivalent of having ingested data at a rate of 200,000,000 events per month (or about 77 events per second) for a year.
Let's try something simple first. We'll grab the distinct count of users for 1 month:
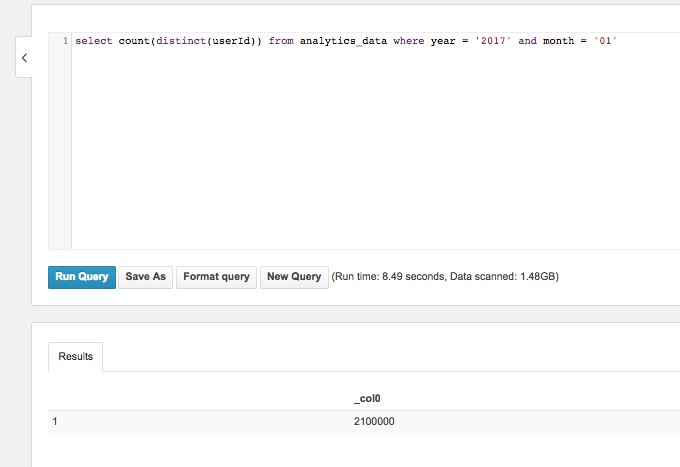
Not exactly blazing speed here at 8 seconds compared to an RDBM, but keep in mind we're not running any servers here. Also, this is all brute force with no indexes, query caches, etc...
As you can see, the scan only read 1.48 GB of data. From this we can see that our partitioning is working correctly.
Next, let's see what kind of gains we've made by using the Parquet file format and query across all partitions for a single column.
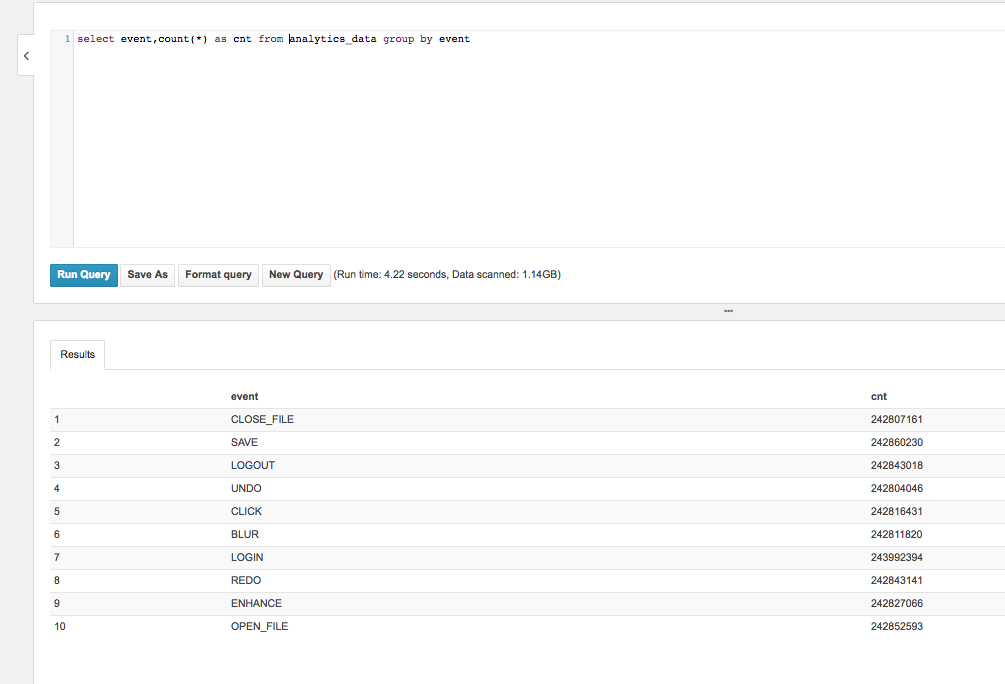
Pretty neat. We've gone over all partitions in 4 seconds, and got the event count for all of them. This time, we had to only read out 1.14 GB of data.
Finally, let's look at the speed when we have to read everything. This query gets the distinct count of users by year and month.
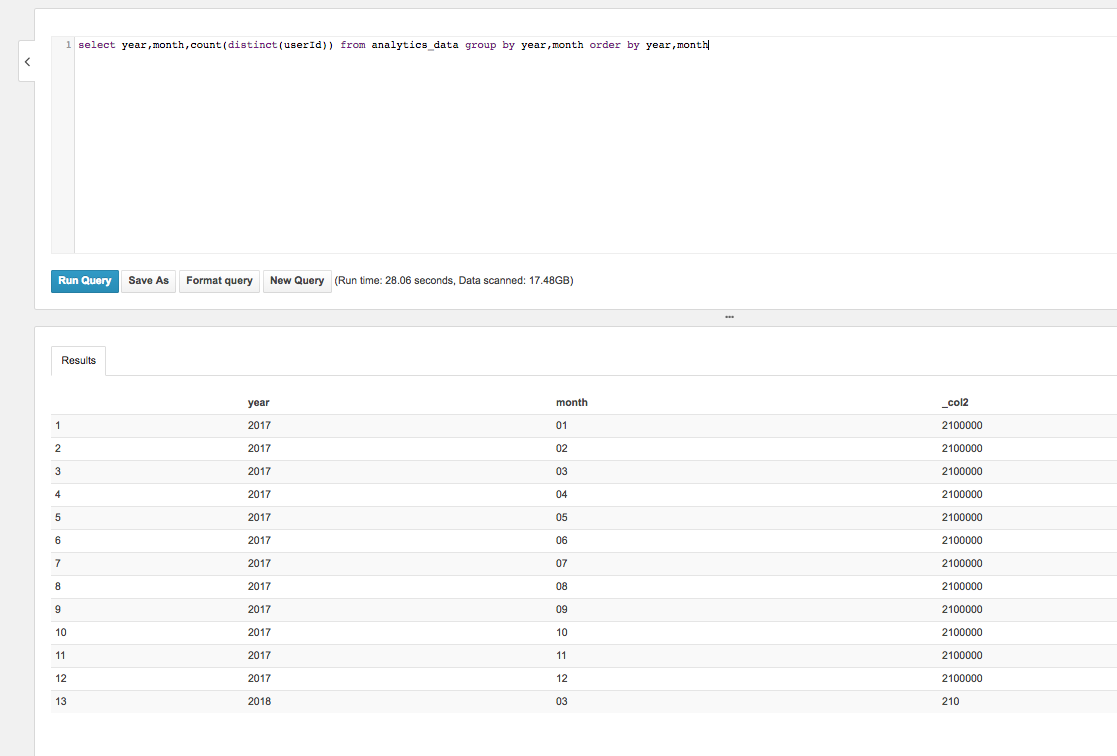
For this query, it took 28 seconds, and scanned almost the entire data set with 17GB of data read.
Building dashboards in QuiskSight
Adding reports on top of this is very straightforward with Quicksight.
Head on over to the Quicksight console.
- From the manage quicksight menu, go to account settings
- Click on Edit AWS permissions
- Make sure you grant access to Athena, as well as to the S3 bucket you've created to store the data
- Create a new data set of type Athena.
- Type in the Athena database name, click create data source
At this point you can optionally import the data into Spice, which will essentially load everything into RAM. Making queries much faster, but also costing more money. Your choice!
Create some reports!
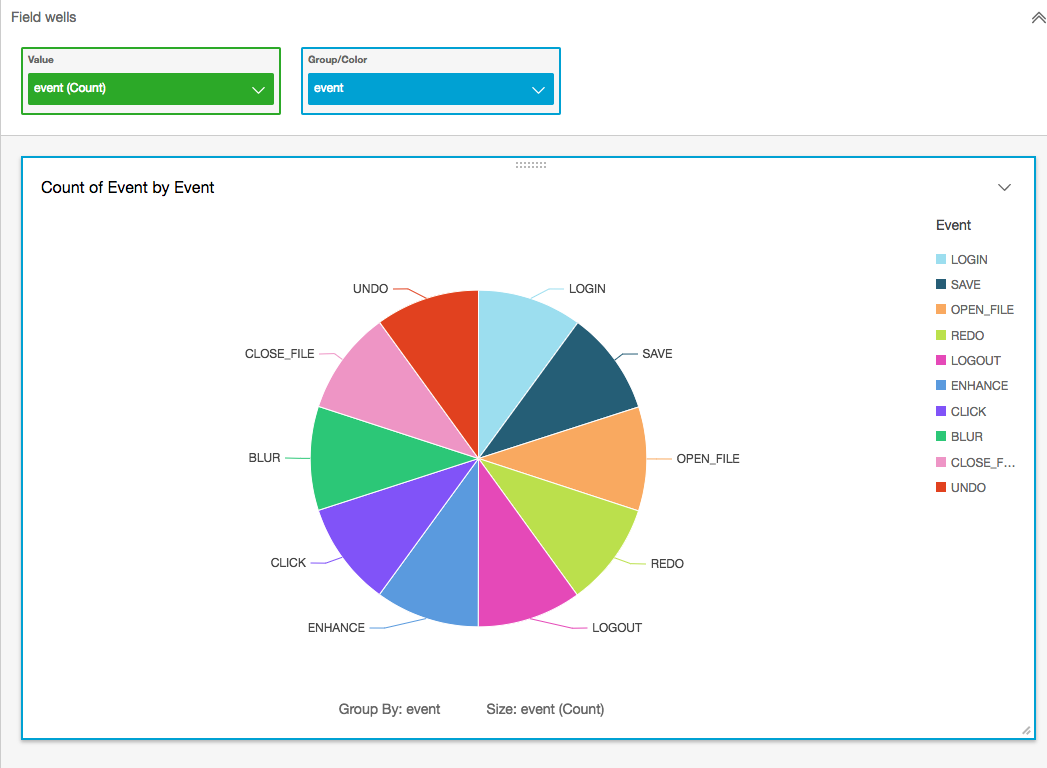
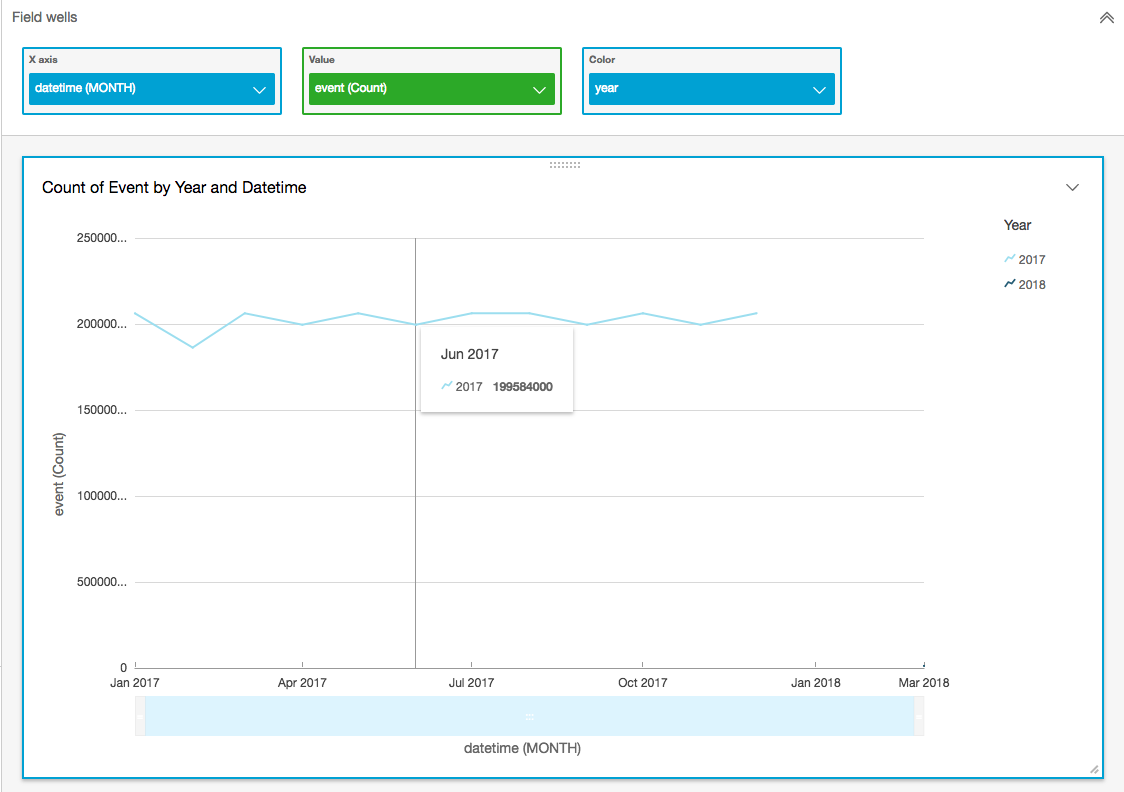
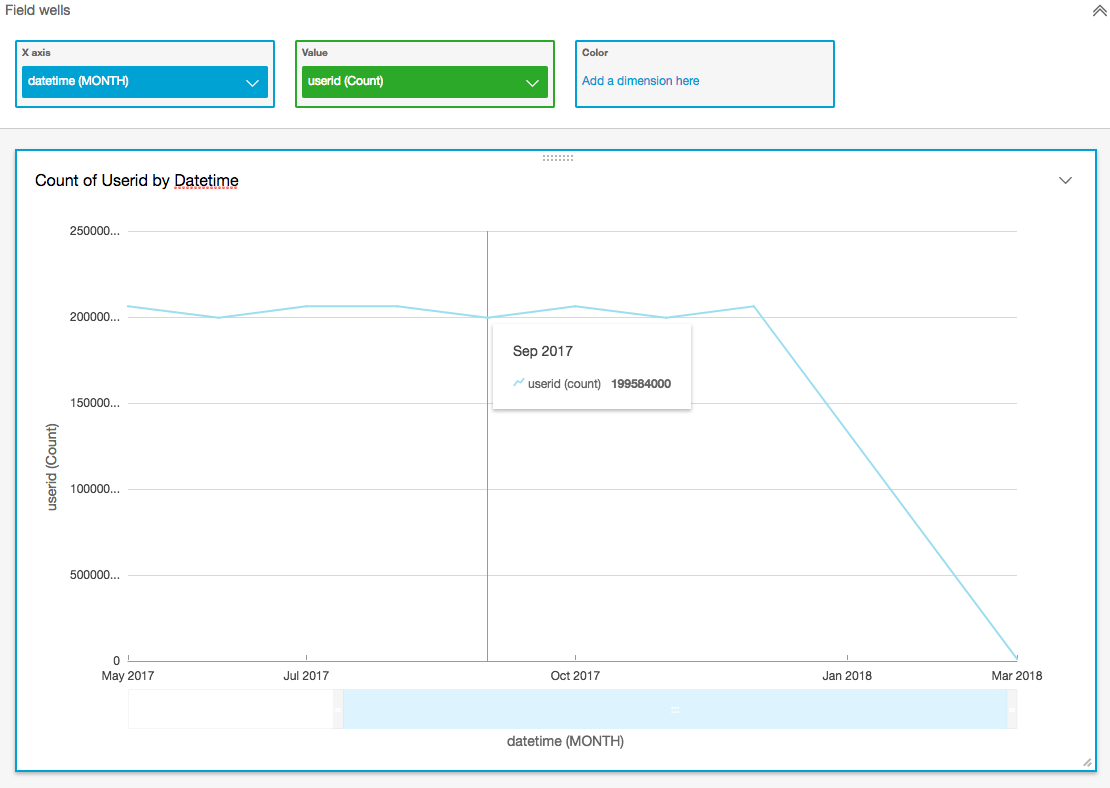
Cost analysis
Assumptions
200 byte payload per event
200,000,000 events per month
200*200,000,000 = 37.25 GB/month
200,000,000/30 (days)/86400 (seconds per day) = 77 requests/sec
200 bytes per event * 77 requests/sec = 15 KB/sec raw throughput
Lambda compute
The compute costs of moving the files around in s3 should be negligible.
200,000,000 lambda invocations per month with 128MB memory @ 100ms runtime.
The monthly compute price is $0.00001667 per GB-s and the free tier provides 400,000 GB-s.
Total compute (seconds) = 200M * (0.1sec) = 20,000,000 seconds
Total compute (GB-s) = 20,000,000 * 128MB/1024 = 2,500,000 GB-s
Total Compute – Free tier compute = Monthly billable compute seconds
2,500,000 GB-s – 400,000 free tier GB-s = 2,100,000 GB-s
2,100,000 GB-s * $0.00001667 = 35.007$/month
Lambda request
200 (million reqs) * 0.2$ (per million): 40$
APIG requests
3.5$ * 200 (million reqs) : 700$/month
Data transfer out: should be very small, api returns only http status code. 5$
S3 storage
37.25 GB/month * 0.023$/GB = 0.86$/month
Data in: free
Data out (to athena/glue): free
After a year it'll be about 10$/month.
S3 requests/operations
Should be negligible.
Athena
5$/TB of data scanned, 10MB minimum query size.
1 year of data is approximately 447GB (149GB compressed)
Cost of scanning entire uncompressed data set once: 2.18$ (0.72$ compressed read)
Realistically, data set can be compressed with snappy and use parquet. Compression should reduce size by a factor of 3. In addition, parquet being a columnar format will further reduce reads by only scanning necessary columns.
Conclusion: depends on query patterns. I'd expect a system using this to implement lots of query caching.
Let's guess at 500TB scanned per month. 500*5: 2500$/month. Probably overkill.
Kinesis firehose
Data ingested 0.029$/GB ingested, 5KB per record min
77 records/sec * 5KB/record / 1024 / 1024 = 0.0003671646118 GB/sec * 30 days/month * 86400 sec/day = 951 GB/month
951 * 0.029 = 27.57$
(overpaying for kinesis here due to 5kb minimum record size...)
Glue ETL
I've run the glue ETL to move from JSON to Parquet, and it took about an hour to run @ 10 DPUs and processed about 20 GB of data. I'd expect the Glue costs for the scenario above to probably run at about 10 hours of runtime per month @ 10 DPUs, so let's guess the cost of that at around 10 hours * 0.44$ (dpu-hour) * 10 (DPUs) = 44$/month
QuickSight
TBD
Total
Lambda (35 + 40) + APIG (705) + S3 (10) + Athena (2500) + Kinesis (27.57) + Glue (44) + QuickSight (??) = 3,361.57$/month.
Closing thoughts
If you've followed along, you can now see that we've got a scalable platform for tracking events. A method for querying them, but no fancy dashboard reporting.
It's easy enough to plug Athena into a BI platform (Pentaho, Tableau, etc... via JDBC) or into QuickSight.
This solution appears to cost about 1/10th of most SaaS providers. I'd chalk this up as a win.